Once the province of computer science, CAPTCHAs—the misshapen digit strings we must decipher and retype on certain websites, thus proving we’re human and not a machine—have finally entered the quaint world of psycholinguistics.
CAPTCHAs, the creation of Carnegie Mellon University computer scientist Luis von Ahn and his then-PhD advisor Manuel Blum, have an oddly arresting backstory. The scientists designed the automated puzzles to separate the people from the spambots: a reverse Turing test of sorts. (Indeed, CAPTCHA stands for “Completely Automated Public Turing test to tell Computers and Humans Apart.”) Despite the occasional hiccup—is that circle a number or a letter?—CAPTCHAs seem to work pretty well.
So well, in fact, we now have reCAPTCHA, which rather ingeniously coerces humans into digitizing old books. Computers usually have little problem detecting and digitizing printed words. But many older books contain passages with faded, uneven, smudged, or otherwise not easily discernable text. With reCAPTCHA, however, instead of web visitors deciphering a single set of squiggles, visitors solve two. The computer already knows the solution to the first, which is used to assay the all-important human-or-bot question. But the second CAPTCHA is a genuine mystery—a portion of an indecipherable old text—so the solutions provided by real human beings are offered as digital translations. In this way, von Ahn and his colleagues reported, digitization is outsourced to you and me, with a level of accuracy rivaling that of paid translators. As of 2008, we’d digitized more than 440 million words of text.
So how do CAPTCHAs (and reCAPTCHAs) work? We already have a pretty good idea why spambots have trouble. As a trio of Newcastle University computer scientists put it not long ago (in a 2011 article available here), “Computers perform better than humans in recognizing individual characters, even under severe distortion. However, locating individual characters in the right order (i.e. segmentation) is in general a computationally expensive and combinatorially hard problem for computers.” In other words, it isn’t determining what the distorted letters are that flummoxes the spambots—it’s figuring out how the letters are positioned, where one begins and another ends.
But why are humans so good at solving CAPTCHAs? Decades of research explain how we identify letters, including how we do so in “noisy” or less than idyllic reading environments. But the new study appears to be the first (or nearly so) to specifically investigate how we decipher CAPTCHAs. Psychologists Thomas Hannagan, Maria Ktori, Myriam Chanceaux, and Jonathan Grainger wondered: Do we rely on fast, automatic processes—processes honed over years of reading letters—or slower, more deliberate ones, such as guess-and-check or processes of elimination? So the researchers tested our ability to glean information from a CAPTCHA when it was presented very quickly.
Their experiment used a masked priming task, which exploits the fact that, when we process a word twice over a relatively short period of time, we’re faster on the second go-around—it has already been “primed.”
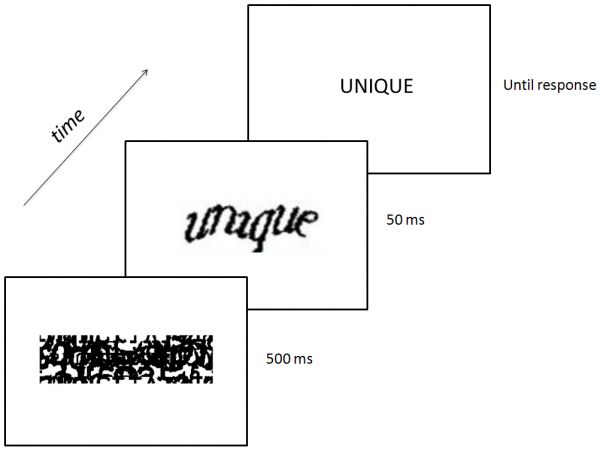
Figure from Hannagan et al., 2012, PLOS ONE
Participants first saw an indecipherable mask (or jumble) on a computer screen. The mask was immediately followed by a prime word, either printed in lowercase letters or scribbled in CAPTCHA form. The prime appeared for just 50 milliseconds—a fifth of how long it takes to read a word under even the best circumstances. Finally, the target appeared, printed in all capital letters. The target was either the same real word that had been presented earlier (either in text or CAPTCHA form), a different real word, or letters that did not spell an English word at all (“TOBLE”). Participants were asked to decide quickly whether the target was a real word. If their responses to the target were faster when it had been preceded by a matching CAPTCHA than a mismatching CAPTCHA, this would suggest that participants had learned something about the CAPTCHA ‘s solution in just a twentieth of a second.
This is indeed what the researchers found: CAPTCHAs prime their text equivalents better than they prime unrelated words. Note, however, that when target words were preceded by regularly printed matching words, responses to the target were even faster. So slower, more conscious processes may also have a role. Still, the researchers attribute our superior CAPTCHA abilities at least partly to the “tolerance” we’ve built over the years for reading altered, rotated, and otherwise transformed text. This raises an obvious empirical question: Are second-grade teachers the best CAPTCHA solvers of all?

